At PEAKUP there is a new “Data” project that we have developed a long time ago in order to provide some data that our own products need from one center instead of keeping it app based. First of all, I want to talk about what the application does and what it contains. We started to develop the project with .NET Core when it first came out and then migrated to .Net Framework to wait a bit more till .NET Core becomes a bit more stable. The data base was designed completely with EntityFramework Code First. We use Azure SQL Server as database. This application alongside the geographical information like continent, country, city also has information that is needed in pretty much any application like 2020/2020 Public Holidays, current weather condition and exchange rates. There are also 2 more Azure Job Projects that connects to more sources and registers data for weather forecast and exchange rates and registers them to both the database and Cache in order to give faster outputs with Redis alongside the web app that we use for the presentation of data in the server.
Why are We Migrating to .Net Core?
First of all, when we take a look at Microsoft’s development efforts for .Net Core and what is going on, it is not hard to foresee that in the long term the developments for .Net Framework will stop after some time of they will be restricted. It is obvious that some stuff I will talk about are possible with .Net Framework as well, but they are not as good as .Net Core for sure and that some problems come up and cause extra time-loss.
Seeing the libraries for features like Image Compression, Video Compression that we want to add to the Project soon are only developed by .Net Core is very important when it comes to cutting the effort for the long-term developments in half.
A big increase in the weather forecast and exchange rates data is observed while the number of users in other PEAKUP products who send request to the application increase. Taking precautions for the upcoming problems of the increase in Response time as the number of requests to the app and data size increase, and web app we use and SQL data base becoming a problem in terms of cost and performance are among the most important reasons.
For now we keep the project in two different Git Branches. We do the developments on Dev, after seeing that everything is okay we merge it to Master and run all the Deployment activities manually during this process. Even though it is not a project that we open and work on frequently, this process being out of manually deployed situation with Azure DevOps and the feature of automatically deploying and running Migrations on database on its own is a development we desire. Doing this more efficiently and faster with .NET Core is more flexible because package management in the project is designed in an easier way.
We used to switch between Azure Service Plans to scale unusual load the customers who changed to apps as SaaS by PEAKUP got when they completed the process once and announced the products to their users. This causes some restrictions on the side of Azure Web Application in terms of costs and scaling the application. The app moving to Containers completely thus Scaling Down itself and run limitless Containers and responding all the request with the same speed or even faster in case of need with Azure DevOps was one of the features we desired. After the tests I did after I migrated the project, I saw that it was too early for the steps concerning Docker and Kubernetes and decided to continue with the web application.
Problems I came across and their Solutions
-
Change in Routing
I started to foresee how achy the migration is going to be when I came across this problem that I spent almost half a day on. There were two GET methods we used in the Interface design in the project and one of them routed all the records and the other routed the data as to Id parameter it got. I researched and found out that it is not allowed yet to prevent faulty designs concerning Routing on .Net Core. For this I decided to continue with a method that acts differently on each occasion by nulling the Id parameter in the method.
-
Different Names in Entity Framework Core
I used all the models we used while developing the project while switching to .NET Core. I was sure that Schema that was going to be on database thanks to Auto Migration was going to be the same but I saw that while domain names where relationships are established on .NET Framework didn’t go through any changes between the areas used for relationships, on .NET Core underscore was added. For this to set up Schema as it is and to migrate the data on Production directly, I utilized the [ForeignKey(“X_Id”)] attribution to make the data on the column suitable with the old standards.
- Database Migration
I imported a copy of around 12GB data to a server on Azure without losing any data on the database. From there I took a data around 12GB that I zipped and downloaded to my computer to my device as a 900MB text and started to try scenarios concerning data migration. Weather, Forecast and Currency tables were the main reason of size being that big. For this I decided to move on by migrating these three tables one by one. I can say that between the scenarios I tried, I did benchmarking in SQL, so to speak.
Even though I ran the file I imported completely on a database and then provided data entry, these actions took too long and after a while if there was a mistake all the time I spent would turn to dust. Therefore I chose the Import Data option that came as default in SQL Management Studio to migrate each line one by one and to see the consistency between the Schemas on two different databases. In this step I saw that Entity Framework created the the data type difference of datetime on .NET Framework and datetime2 on .NET Core.
I went back to the project and added the [Column(TypeName = “datetime”)] attribute in the beginning of the Datetime fields and made sure that it stayed that way for the data migration on Schema and imported it successfully to my device in 15 minutes.
To run an EF Core database on Production I deployed both the data base and the application by opening the Web Application. I decided to go on with the Linux Web Application I used for .NET Core and then had some problems. I talked about them in the upcoming steps.
-
Library Change on the Cache Layer
We used to use the ServiceStack.Redis library that had a better performance and API design and that offered a cache memory solution with a higher performance with its specially developed JSON library. But since the Nuget library on which we did this development hasn’t been updated for a long time thus we stayed away from this benefit and we didn’t see its performance concerning Connection Pooling I changed to Stack.Exchange.Redis Library developed by StackOverFlow.
-
Critical Lacks in Text. Json
I can say that Microsoft has been obsessed with developing System.Text and all libraries under it for performance and JSON actions of .NET Core for a long time. I have been following that there is an increase of performance in almost all Framework versions in a lot of projects that use System.Text Namespace when benchmarking tests are done. I thought and guessed that a library coming from Built would be better in JSON’s routing in API to get rid of Newon.Json’s and ServiceStack.Redis’ JSON library data reading-writing to Cache. But than a huge disappointment waved at me! Cause I saw in the Microsoft Document published about migrating from Newton.Json that many features like PreserveReferencesHandling, ReferenceLoopHandling haven’t been developed.
-
Features in Linux Web Application that haven’t been completed on Azure
First I ran the application in a standard way that I can manually test and then run performance test without waiting for a Pipeline and to continue after Staging. I started the action by publishing and came across a 1-hour disruption on Azure by chance and thought that there was something wrong with the application. After losing two hours I found out that there was an incident on Microsoft and some issue might occur on the European continent that we work on. At that point I started to work on the next steps on the application. And I realized that the disruption was a blessing!
Some of the data we import concerning exchange rates and forecast flow instantly and some of them flow hourly. We dealt with them without leaving the job as Azure Job before anyways. I couldn’t find the Web Job tab inside the Web Application to observe some problems about it staying the same way and what will happen! First I thought it might have to do with the Tier of the application so I moved to an upper Tier and Web Job didn’t come back. Then when I did some research I found out that Linux type Azure Web Applications lacked a lot of things. Without waiting for the disruption to be over I deleted the application and continued by opening a new Windows type web application.
The reason I made that decision had to do with the structure continuing through Kubernetes and Container depending on the success of Load tests.
-
Load Testing
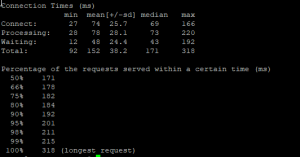
There is a paid and an unpaid tool developed by the engineering team of SendLoop know by everyone as an e-mail marketing company. I always wait for the first test to go through here with this tool that you can reach on https://loader.io/ and then do the load tests with EU project of Apache. The first test with this tool that goes up to 10.000 requests was pretty successful. A serious decrease was seen in response time but after a while the application would start to slow down.
I realized that there was an unreasonable expansion in Memory in Web Application and that after a point there was no space even a space of 1 MB. When I analyzed the requests I saw that the method I used was going on with AddAndWrite scenario instead of OverWrite on the given Key of data! I solved this problem right away and continued the tests after upgrading the packages.
After I saw that requests passed successfully on SendGrid I started to do tests with the EU Tool. For this I used a server that had a very good internet connection. Now everything is ready and I can move on to the last step on DevOps.
-
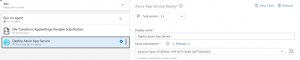
Changes in DevOps Pipeline Setup
After I turned the project into a condition that received requests, I started to separate it into three Stages: Production that I talked about in the beginning of the article, Beta that works with a live environment and code development and DEV. First I completed the migration in a way that Master, i.e. Production would follow the sequence.
And I came across an interface change Azure did on DevOps Pipeline. I found out that the infrastructure of the library i.e. changes done concerning ConnectionString, special keys etc. are added as a Step while migrating Artifact output to the Release step with a Versioning system now.