PEAKUP’da kendi ürünlerimizin ihtiyacı olan bazı veriyi uygulama bazlı tutmak yerine tek bir merkezden sağlamak üzere uzun zaman önce geliştirdiğimiz bir “Data” projesi bulunuyor. Öncelikle biraz uygulamanın ne yaptığından ve neleri barındırdığından bahsetmek istiyorum. Projeyi henüz .NET Core ilk çıktığında geliştirmeye başlayıp, .NET Core’un biraz daha stabil hala gelmesini beklemek için .Net Framework ile geliştirdik. Veri tabanı tamamen EntityFramework Code First ile tasarlandı. Veri tabanı olarak Azure SQL Server kullanıyoruz. Bu servis içerisinde hemen hemen her uygulamada ihtiyaç duyulan; kıta, ülke, şehir gibi coğrafi bilgilerin yanında 2020, 2021 yılı resmî tatil günleri, anlık hava durumu bilgisi ve döviz kuru ve benzeri gibi bilgiler yer almaktadır. Servis içerisinde verilerin sunumu için kullandığımız web uygulamasının yanında, hava durumu ve döviz için birden fazla kaynağa bağlanıp veri çeken ve bunları hem veri tabanına hem de Redis ile daha hızlı çıktılar vermek için Cache’e yazan iki Azure Job projesi daha bulunmaktadır.
Neden .Net Core’a Geçiş Yapıyoruz?
Öncelikle Microsoft’un .Net Core için uzun süredir yaptığı geliştirme eforuna ve olup bitene baktığımızda .Net Framework için uzun vadede geliştirmelerin bir süre sonra duracağını ya da kısıtlı bir hale geleceğini ön görebilmek hiç zor değil. Anlatacağım birtakım şeyler .Net Framework ile de mümkün olsa da çıktılarının .NET Core kadar iyi olmadığı ya da süreç içerisinde ekstra zaman kaybına sebep olan bazı sorunlar yaşandığı aşikâr!
Projeye yakın zamanda eklemek istediğimiz; Image Compression, Video Compression gibi özellikler için arayıp bulduğumuz kütüphanelerin yalnızca .Net Core tarafında geliştirildiğini görmek, daha uzun vadede yapılacak geliştirmeler için bu eforu neredeyse yarı yarıya düşürmek anlamında çok önemli durumdadır.
Uygulamaya istek gönderen diğer PEAKUP ürünlerindeki kullanıcı sayısı giderek artarken dolaylı olarak tuttuğumuz hava durumu ve döviz verisinde de büyük bir artış gözlemleniyor. Uygulaya gelen istek sayısı ve verinin büyüklüğü arttıkça Response sürelerindeki artış ve hem web uygulamasının hemde kullandığımız SQL veri tabanının artık maliyet ve performans olarak bir probleme dönüşmesinin önünü almak en önemli sebepler arasında yer almaktadır.
Şu anda projeyi standart bir şekilde iki ayrı Git Branch’inde tutuyoruz. Geliştirmeleri Dev’de yapıp, her şeyin tamam olduğunu gördükten sonra master’a Merge edip bütün süreçteki Deployment faaliyetini manuel olarak yürütüyoruz. Sık sık açıp üzerinde geliştirme yaptığımız bir proje olmasa da bu sürecin Azure DevOps ile tamamen manuel ve elle Deploy edilir bir halden çıkartılıp. Otomatik olarak Deploy eden, veri tabanında Migration’ları kendisi çalışan bir hale doğru ilerlemesi arzu ettiğimiz bir geliştirme süreci, bunu .NET Core ile daha verimli ve daha hızlı bir şekilde yapmanın önü .NET Framework’e göre oldukça daha esnek zira proje içerisinde paket yönetimi daha kolay bir şekilde tasarlanmış.
PEAKUP tarafından tamamen SaaS olarak geliştirilen uygulamalara geçiş yapan müşterilerin, bütün süreci bir kerede tamamlayıp kullanıcılarına ürünleri duyurduklarına gelen sıra dışı yükü Scale etmek için uygulama tarafında sürekli Azure Servis Planları arasında geçiş yapmaktaydık. Bu hem maliyet olarak hem de uygulamayı Scale etmek konusunda Azure Web Application tarafında birtakım kısıtlamalara neden oluyordu. Azure DevOps ile uygulamanın tamamen Container’lara taşınarak hem kendini Scale Down yapıp hem de ihtiyaç durumunda sınırsız sayıda Container ayağa kaldırarak bütün taleplere, aynı ve hatta daha yüksek hızda cevap vermesi de olmasını istediğimiz özelliklerden birisiydi! Projeyi geçirdikten sonra yaptığım testler ile aslında Docker ve Kubernetes ile ilgili atılacak adımlar için çok erken olduğunu gördükten sonra web uygulamasıyla devam etmeye karar verdim.
Karşılaştığım Problemler ve Çözümleri
- Routing’de Değişiklik
Üzerinde neredeyse yarım günlük efor harcadığım bu problemle karşılaştığımda geçişin ne kadar sancılı olacağını tahmin etmeye başladım. Proje içerisinde kullandığımız Interface tasarımında iki adet GET metodu bulunuyordu ve bunlardan bir tanesi tüm kayıtları ötekiyse aldığı Id parametresine göre verileri döndürüyordu. Net Core tarafındaki Routing ile ilgili hatalı tasarımların önüne geçilmek için bu daha izin verilmediğini araştırarak öğrendim. Bu nedenle metot içerisindeki Id parametresini Nullable yaparak duruma göre farklı davranan tek bir metot ile devam etmeye karar verdim.
- Entity Framework Core’daki Değişen İsimlendirmeler
Projeyi geliştirirken kullandığımız modellerin tamamını .NET Core’a geçerken birebir kullandım. Auto Migration sayesinde veri tabanında çıkacak Schema’nın birebir olmasından emindim ancak .NET Framework tarafında ilişkilerin kurulduğu alan isimleri herhangi bir karakter değişimine uğramazken .NET Core’da ilişki için kullanılan alanlar arasında alt çizgi eklendiğini gördüm. Bu nedenle Schema’yı birebir kurmak ve direkt olarak Production’daki verileri taşıyabilmek için haliyle [ForeignKey(“X_Id”)] Attribute’undan faydalanarak kolonlardaki verinin eski standartlara uymasını sağladım.
- Veri Tabanın Taşınması
Veri tabanında hiçbir veri kaybetmeden yaklaşık 12GB civarındaki verinin kopyasını Azure üzerindeki bir sunucuya çektim. Oradan kendi bilgisayarıma zipleyerek indirdiğim için 12GB civarındaki veriyi 900MB text olarak kendi makineme aldım ve verinin geçişi ile ilgili senaryoları denemeye başladım. Weather (eski hava durumu verisi), Forecast (yeni yayına aldığımız hava durumu verisi) ve Currency tabloları bu veri tabanındaki büyüklüğün başlıca sebeplerindendi. Bu nedenle bu üç tabloyu tek tek geçirerek ilerlemeye karar verdim. Denediğim senaryolar arasında SQL içerisinde adeta benchmarking yaptığımı söyleyebilirim.
Çektiğim dosyayı komple bir veri tabanı üzerinde ayağa kaldırıp ardından verilerin girişini sağlasam da işlemler hem uzun sürüyor hem de belli bir yerden sonra hata verdiğinde bütün süre boşa gidiyordu. Bu nedenle her bir satırın tek tek taşınması ve iki farklı veri tabanındaki Schema’ların birbiri arasındaki uyumu görmek için SQL Management Studio içerisinde varsayılan olarak gelen Import Data seçeneğini tercih ettim. Bu aşamada Entity Framework’ün tarih tipindeki alanlar için .NET Framework’de datetime, .NET Core’da da datetime2 veri tipi farklılığı yarattığını gördüm.
Tekrar projeye dönüp Datetime alanlarının başına [Column(TypeName = “datetime”)]
Attribute’unu ekleyerek bu alanlarında Schema’da veri geçişi için bu şekilde kalmasını sağladım ve verileri başarılı bir şekilde kendi makinamda 15 dakikada taşıdım.
Production’da artık bir EF Core veri tabanı ayağa kaldırmak için Web Uygulaması açarak hem veri tabanını hem de uygulamayı Deploy ettim. Burada .NET Core kullandığım için Linux tipindeki Web Application ile ilerlemeye karar verdim ve sonrasında bazı problemler yaşadım. Bununla ilgili bir sonraki adımlarda bahsettim.
- Cache Katmanında Kütüphane Değişikliğine Gidilmesi
Hem performans hem de API tasarımı daha iyi olmasının yanında kendisine özel geliştirilen JSON kütüphanesi ile daha performanslı bir önbellek çözümü sunan ServiceStack.Redis kütüphanesini kullanmaktaydık. Ancak hem bu geliştirmeyi yaptığımız Nuget kütüphanesinin uzun zamandır güncellenmediği için bu faydadan uzak kaldığımız hemde Connection Pooling ile ilgili performansını yeterince göremediğimiz için StackOverFlow tarafından geliştirilen StackExchange.Redis kütüphanesine geçiş yaptım.
- Text. Json’daki Kritik Eksiklikler
Microsoft’un .NET Core içerisinde hem performans hem de JSON işlemleri için uzun zamandır saplantılı bir şekilde System.Text ve altındaki bütün kütüphanelerde geliştirme yaptığını söyleyebilirim. Benchmarking testleri yapıldığında System.Text Namespace’ini kullanan bir çok projede neredeyse her Framework versiyonunda büyük bir performans artışı görüldüğünü uzun zamandır takip ediyordum. Hem Newton.Json hemde ServiceStack.Redis’in JSON kütüphanesinden kurtulmak için API’dan dönen JSON’ları ve Cache’e veri okuma-yazma işlerinde Built’in gelen bir kütüphanenin daha iyi olacağını düşünerek tahmin ettim. Ancak sonrasındaki hayal kırıklığı çok büyük oldu! Zira Newton.Json’dan geçişle ilgili yayınlanan Microsoft dokümanında PreserveReferencesHandling, ReferenceLoopHandling gibi birçok özelliğin henüz geliştirilmediğini gördüm. Bu nedenle Built’in gelen bütün kodu geriye aldım ve Newton.Json ’la devam ettim.
- Linux Web Uygulamasında Azure Tarafında Tamamlanmamış Özellikler
Uygulamayı öncelikle elle test edebileceğim ve sonrasında performans testleri yapabileceğim, herhangi bir Pipeline beklemeden, Staging sonradan devam etmek üzere standart bir şekilde ayağa kaldırdım. Publish ederek işlemi başlattım ve o gün Azure’da yaşanan bir saatlik bir kesinti ile şans eseri karşılaşıp uygulamada bir problem olduğunu düşündüm. İki saatimi kaybettikten sonra Microsoft tarafında bir Incident yaşandığını ve çalıştığımız Avrupa kıtasındaki bazı işlemlerde problem olabildiği bilgisini aldım. O sırada uygulamanın sonraki adımlarını incelemek üzere diğer çalışmalara başladım. Fark ettim ki kesintiyi iyi ki yaşamışım!
Döviz ve hava durumu ile ilgili çektiğimiz verilerin bazıları anlık akarken bazılarıysa saatlik gelmektedir. Bunları uygulama içerisinden çıkmadan, Azure Job olarak zaten daha öncesinde de ilerletiyorduk. Aynı şekilde kalmasına ve olacaklar ile ilgili problemleri gözlemek için Web Application içerisinde Web Job sekmesini aradığımda sekmeyi bulamadım! Önce uygulamanın Tier’ı ile alakalı olabileceğini düşündüğüm bu problem için uygulamayı bir üst Tier’a geçirdim ve Web Job tekrar gelmedi. Sonrasında araştırdığımda henüz Linux tipindeki Azure Web Application’larda birçok şeyin eksik olduğunu öğrendim. Kesintinin bitmesini beklemeden direkt uygulamayı sildim ve Windows tipinde yeni bir web uygulaması açarak devam ettim.
Bu aşamada bu kararı vermemin sebebi Load testlerde yakalanacak başarıya göre yapının tamamen Kubernetes ve Container üzerinden devam etmesiyle ilgili oldu.
- Load Testlerin Yapılması
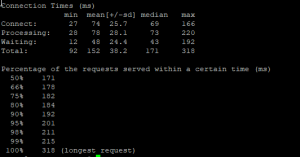
Herkesin Email Marketing şirketi olarak bildiği SendLoop’un mühendislik takımı tarafından geliştirilen hem ücretli hem de ücretsiz bir aracı bulunuyor. https://loader.io/ adresinden erişebileceğiniz bu Tool ile her zaman önce ilk testin buradan geçmesini bekler sonrasında da Apache’nin AB projesi ile yük testlerini gerçekleştiririm. 10,000 isteğe kadar çıkan bu ücretsiz Tool ile ilk test oldukça başarılıydı. Response Time’da ciddi düşüşler görülüyor ancak uygulama belli bir süre sonra yavaşlamaya başlıyordu.
Azure içerisinde Web Application’da Memory’de anlamsız bir şişme ve bir yerden sonra 1MB boyutunda bile yer kalmadığını fark ettim. İstekleri incelediğimde Redis Cache içerisinde kullandığım metodun verinin verilen Key üzerinde OverWrite yerine AddAndWrite senaryosu ile ilerlediğini fark ettim! Hemen bu problemi çözüp paketleri güncelledikten sonra testlere devam ettim.
SendGrid tarafında isteklerin başarılı bir şekilde geçtiğini gördükten sonra AB Tool’u ile testler yapmaya başladım. Bunun için internet bağlantısı çok iyi olarak bir sunucuyu kullandım. Artık her şey hazır ve DevOps’daki son adıma geçebilirdim.
- DevOps Pipeline Kurulumundaki Yenilikler
Projeyi artık istek alır hale getirdikten sonra makalenin girişinde de bahsettiğim Production, canlı ortam ve son kod geliştirmesiyle birlikte çalışan Beta ve DEV olacak şekilde üç Stage’e ayırmaya başladım. Önce Master yani Production sonrasında da silsileyi takip edecek şekilde geçişleri tamamladım. Her bir Stage için ayrı veri tabanı açtım ve hepsini Master’dan taşımaya devam ettim.
Azure’un DevOps Pipeline’ında yaptığı bir arayüz değişikliği ile ilk defa karşılaştım. Artifact çıktısını Release adımına geçirirken burada bir Versionlama sistemiyle artık kütüphane alt yapısının yani ConnectionString, özel anahtarlar gibi ayarlar ile ilgili yapılan değişikliklerin de bir Step olarak eklendiğini öğrendim.